Building a flexible API
@app-core
└── /resolvers/... # <- Reusable back-end logic goes hereTo get an idea of API design in portable workspaces, inspect the file tree below:
- getPost.bridge.ts
- getPost.resolver.ts ←
- getPost.query.ts
- getPost.fetcher.ts
- ...
- addPost.bridge.ts
- addPost.resolver.ts ←
- addPost.fetcher.ts
- api / posts / create / route.ts
- api / posts / [slug] / route.ts
This doc focuses on creating APIs that:
- Are self-documenting, easy to use, reuse and maintain
- Keep input + output shape, validation and types in sync automatically
- Portable as part of a fully copy-pasteable feature
You’ll learn to create an API that can be:
- ✅ Reused as functions / promises anywhere else in your back-end
- ✅ A Next.js API route handler
- ✅ An RPC style GraphQL resolver
Using the API generator
Creating a new API that checks all the above boxes can involve a lot of boilerplate.
To avoid that + have this boilerplate code generated, you can use the following command:
npm run add:resolverThis will ask you a few questions about your new API, and then generate + link the necessary files for you.
>>> Modify "your universal app" using custom generators
? Where would you like to add this resolver? # (use arrow keys)
❯ features/@app-core -- importable from: '@app/core'
features/@some-feature -- importable from: '@app/some-feature'
features/@other-feature -- importable from: '@app/other-feature'⬇⬇⬇
>>> Modify "your universal app" using custom generators
? Where would you like to add this resolver? # -> features/@app-core
? How will you name the resolver function? # -> getExampleData
? Optional description: What will the resolver do? # -> Get some test data
? What else would you like to generate? # -> GraphQL Resolver, GET & POST API Routes
? Which API path would you like to use? # -> /api/example/[slug]
>>> Changes made:
• /features/app-core/schemas/getExampleData.bridge.ts (add)
• /features/app-core/resolvers/getExampleData.resolver.ts (add)
• /features/app-core/routes/api/example/[slug]/route.ts (add)
>>> Success!To explain what happens under the hood, have a look at the following steps. It’s what the generator helps you avoid doing manually:
Manually add a new API
It’s worth noting that it’s fine to reuse the Next.js or Expo ways of working to create APIs. We just provide a more portable and structured way to do so:
Start from a DataBridge
Schemas serve as the single source of truth for your data shape. But what about API shape?
You can combine input and output schemas into a bridge file to serve as the single source of truth for your API resolver. You can use createDataBridge to ensure all the required fields are present:
import { Post } from '../schemas/Post.schema'
import { createDataBridge } from '@green-stack/schemas/createDataBridge'
/* -- Bridge ------------- */
export const updatePostBridge = createDataBridge({
// Assign schemas
inputSchema: Post.partial(), // You can create, reuse or extend schemas here if needed
outputSchema: Post,
// Used for GraphQL defs
resolverName: 'updatePost',
resolverArgsName: 'PostInput',
// API config
apiPath: '/api/posts/[slug]/update',
allowedMethods: ['POST', 'GRAPHQL'],
})Don’t worry too much about the GraphQL and API route config for now. We’ll get to that soon.
Think of a “Databridge” as a literal bridge between the front and back-end.
It’s a metadata object you can use from either side to provide / transform / extract:
- ✅ Route handler args from request params / body
- ✅ Input and output types + validation + defaults
- ✅ GraphQL schema definitions for
schema.graphql - ✅ The query string to call our GraphQL API with
There’s two reasons we suggest you define this “DataBridge” in a separate file:
-
- Reusability: If kept separate from business logic, you can reuse it in both front and back-end code.
-
- Consistency: Predicatable patterns make it easier to build automations and generators around them.
For this reason, we suggest you add
.bridge.tsto your bridge filenames.
Add your business logic
- updatePost.bridge.ts
- updatePost.resolver.ts ← Here
Let’s use the data bridge we just created to bundle together the input and output types with our business logic.
You can do so by creating a new resolver file and passing the bridge as the final arg to createResolver at the end. The first argument is your resolver function containing your business logic:
import { createResolver } from '@green-stack/schemas/createResolver'
import { updatePostBridge } from './updatePost.bridge'
import { Posts } from '@db/models'
/** --- updatePost() ---- */
/** -i- Update a specific post. */
export const updatePost = createResolver(async ({
args, // <- Auto inferred types (from 'inputSchema')
context, // <- Request context (from middleware)
parseArgs, // <- Input validator (from 'inputSchema')
withDefaults, // <- Response helper (from 'outputSchema')
}) => {
// Validate input and apply defaults, infers input types as well
const { slug, ...postUpdates } = parseArgs(args)
// -- Context / Auth Guards / Security --
// e.g. use the request 'context' to log out current user
const { user } = context // example, requires auth middleware
// -- Business Logic --
// e.g. update the post in the database
const updatedPost = await Posts.updateOne({ slug }, postUpdates)
// -- Respond --
// Typecheck response and apply defaults from bridge's outputSchema
return withDefaults({
slug,
title,
content,
})
}, updatePostBridge)You pass the bridge (☝️) as the second argument to
createResolver()to:
- 1️⃣ infer the input / arg types from the bridge’s
inputSchema - 2️⃣ enable
parseArgs()andwithDefaults()helpers for validation, hints + defaults - 3️⃣ automatically extract the request context whether in an API route / GraphQL resolver / …
The resulting function can be used as just another async function anywhere in your back-end.
The difference with a regular function, since the logic is bundled together with its data-bridge / input + output metadata, is that we can easily transform it into APIs:
Turn resolver into an API route handler
We recommend workspaces follow Next.js API route conventions. This is so our scripts can automatically re-export them to the
@app/nextworkspace later.
- updatePost.bridge.ts
- updatePost.resolver.ts
- route.ts ← Here
You can create a new API route by exporting a GET / POST / UPDATE / DELETE handler assigned to a createNextRouteHandler() that wraps your “bridged resolver”:
import { updatePost } from '@app/resolvers/updatePost.resolver'
import { createNextRouteHandler } from '@green-stack/schemas/createNextRouteHandler'
/* --- Routes ------------ */
export const UPDATE = createNextRouteHandler(updatePost)
// Automatically extracts (☝️) args from url / search params
// based on the zod 'inputSchema'
// If you want to support e.g. POST (👇), same deal (checks request body too)
export const POST = createNextRouteHandler(updatePost)What createNextRouteHandler() does under the hood:
-
- extract the input from the request context
-
- validate it
-
- call the resolver function with the args (and e.g. token / session / request context)
-
- return the output from your resolver with defaults applied
Check Next.js Route Handlers to understand supported exports (like
GETorPOST) and their options.
Restart your dev server or run
npm run link:routesto make sure your new API route is available.
GraphQL, without the hassle
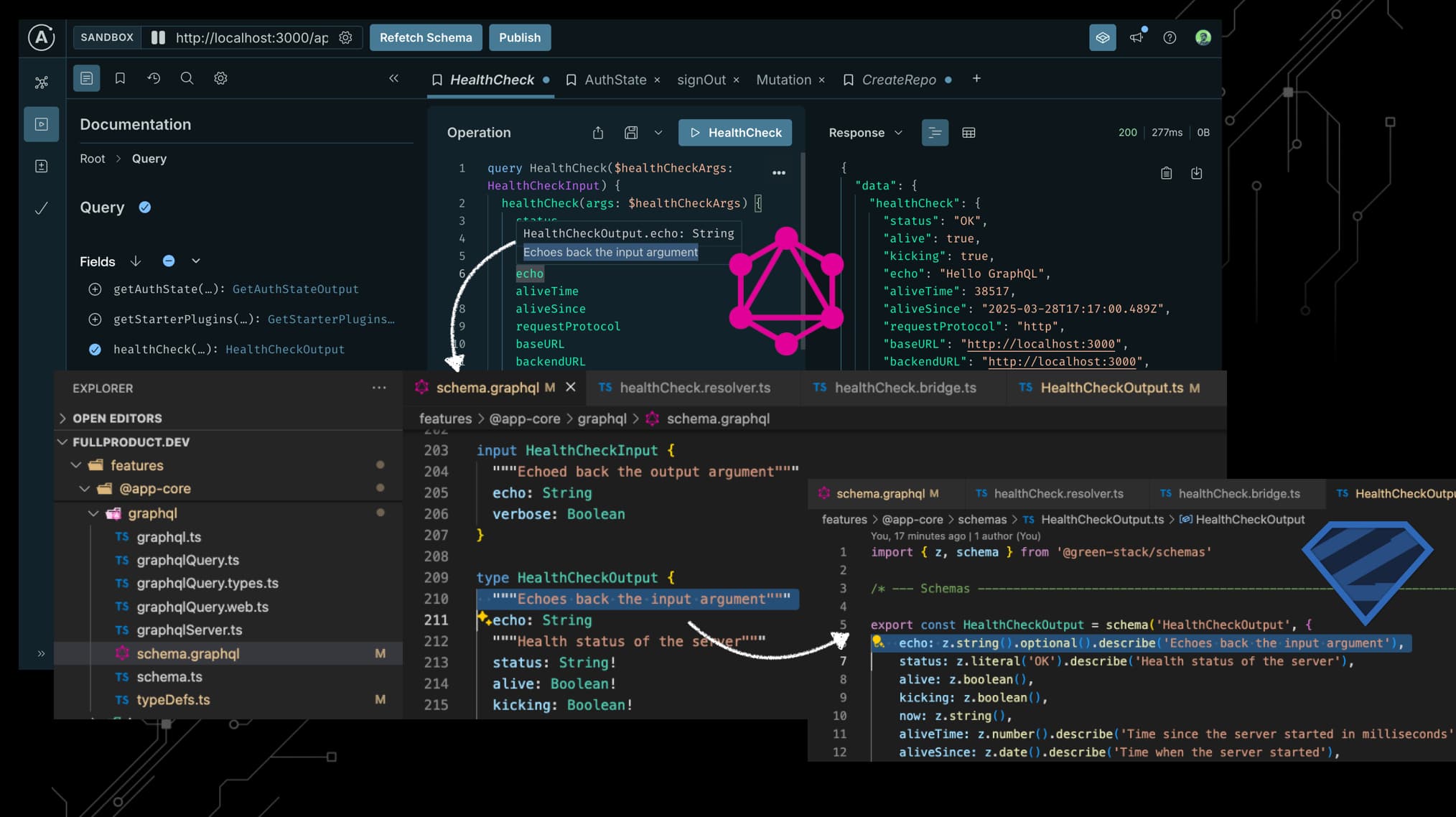
API routes are fine, but we think GraphQL is even better, if you don’t have to deal with the hassle of managing it. So we made it quite easy to enable GraphQL for your resolvers. The flow is quite similar.
In the same file, add the following:
import { updatePost } from '@app/resolvers/updatePost.resolver'
import { createNextRouteHandler } from '@green-stack/schemas/createNextRouteHandler'
import { createGraphResolver } from '@green-stack/schemas/createGraphResolver'
/* --- Routes ------------ */
// exports of `GET` / `POST` / `PUT` / ...
/* --- GraphQL ----------- */
export const graphResolver = createGraphResolver(updatePost)
// Automatically extracts input (☝️) from graphql request contextAfter exporting graphResolver here, restart the dev server or run npm run build:schema manually.
This will:
-
- pick up the
graphResolverexport
- pick up the
-
- put it in our list of graphql compatible resolvers at
resolvers.generated.tsin@app/registries
- put it in our list of graphql compatible resolvers at
-
- recreate
schema.graphqlfrom input & output schemas from registered resolvers
- recreate
You can now check out your GraphQL API playground at /api/graphql
Optional - Add a universal fetcher
We’ll mostly be using fetchers when providing data to our app screens or routes. You can skip this step as it will be covered on the next page as well.
How to turn a DataBridge into a fetcher?
One reason we recommed GraphQL is that it’s easier to make a universal fetcher that:
- can run on the server, browser or mobile
- automatically builds the query string from the input and output schemas
- is auto typed if using the bridge to provide the query
- is auto typed with
gql.tadaif a custom query is used (alt)
- updatePost.bridge.ts
- updatePost.resolver.ts
- updatePost.query.ts ←
The easiest way to create a fetcher is to use the bridgedFetcher() helper:
import { updatePostBridge } from './updatePost.bridge'
// ☝️ Reuse your data bridge
import { bridgedFetcher } from '@green-stack/schemas/bridgedFetcher'
// ☝️ Universal graphql fetcher that can be used in any JS environment
/* --- updatePostFetcher() --------- */
export const updatePostFetcher = bridgedFetcher(updatePostBridge)This will automatically build the query string with all relevant fields from the bridge.
To write a custom query with only certain fields, you can use our graphql() helper with bridgedFetcher():
import { ResultOf, VariablesOf } from 'gql.tada'
// ☝️ Type helpers that interface with the GraphQL schema
import { graphql } from '../graphql/graphql'
// ☝️ Custom gql.tada query builder that integrates with our types
import { bridgedFetcher } from '@green-stack/schemas/bridgedFetcher'
// ☝️ Universal graphql fetcher that can be used in any JS environment
/* --- Query ----------------------- */
// VSCode and gql.tada will help suggest or autocomplete thanks to our schema definitions
export const updatePostQuery = graphql(`
query updatePost ($updatePostArgs: UpdatePostInput) {
updatePost(args: $updatePostArgs) {
slug
title
body
}
}
`)
// ⬇⬇⬇ automatically typed as ⬇⬇⬇
// TadaDocumentNode<{
// updatePost(args: Partial<Post>): {
// slug: string | null;
// title: boolean | null;
// body: boolean | null;
// };
// }>
// ⬇⬇⬇ can be turned into reusable types ⬇⬇⬇
/* --- Types ----------------------- */
export type UpdatePostQueryInput = VariablesOf<typeof updatePostQuery>
export type UpdatePostQueryOutput = ResultOf<typeof updatePostQuery>
/* --- updatePostFetcher() --------- */
export const updatePostFetcher = bridgedFetcher({
...updatePostBridge, // <- Reuse your data bridge ...
graphqlQuery: updatePostQuery, // <- ... BUT, use our custom query
})Whether you use a custom query or not, you now have a fetcher that:
- ✅ Uses the executable graphql schema serverside
- ✅ Can be used in the browser or mobile using fetch
Why GraphQL?
As mentioned before, the ‘G’ in GREEN-stack stands for GraphQL. But why do we recommend it?
GraphQL may look complex, but when simplified, you can get most benefits without much complexity:
- Type safety: Your input and output types are automatically validated and inferred. (from bridge or gql.tada )
- Self-documenting: The API is automatically documented in
schema.graphql+ introspection.
If you don’t need to worry much setting up and consuming GraphQL, it’s quite similar to using tRPC.
It’s important to note that there are some common footguns to avoid when using GraphQL:
Why avoid a traversible graph?
If you don’t know yet, the default way to use GraphQL is to expose many different domains as a graph.
Think of a graph based API as each data type being a node, and each relationship between them being an edge. Without limits you could infinitely traverse this graph. Such as a User having Post nodes, which in themselves have related Reply data, which have related User data again. You could query all of that in one go.
That might sound great, but it can lead to problems like:
- Performance: If not limited, a single query could request so much data it puts a severe strain on your server.
- Scraping: If you allow deep nesting, people might more easily scrape your entire database.
Instead of exposing all of your data as a graph, we recommend you use GraphQL in a more functional “Remote Procedure Call” (RPC) style.
Only when actually offering GraphQL as a public API to third party users to integrate with you, do we recommend a graph / domain style GraphQL API.
Why RPC-style GraphQL?
If you’re not building a public API, you should shape your resolvers in function of your front-end screens instead of your domain or database collections. This way, you can fetch all the data required for one screen in one go, without having to call multiple resolvers or endpoints.
To illustrate RPC-style queries in your mind, think of
getDashboardData()vs. having to call 3 separateOrders(),Products(),Transactions()type resolvers to achieve the same thing.
When used in this manner, quite similar to tRPC, it remains the best for initial data-fetching. Though mutating data might be better served as a tRPC call or API route POST / PUT / DELETE request.
We think GraphQL is great for fetching data, but not always the best for updating data. Especially when you need to handle complex forms and file uploads.
You might therefore want to handle mutations of data in a more traditional REST-ful way, using tRPC or just plain old API routes / handlers.
Securing your API
By default, any API generated by the add:resolver command is open to the public. Consider whether this is the right choice for that specific API.
To prevent unauthorized acces, you likely want to:
- expand the Next.js Middleware
- or add auth checks in your business logic
We offer some solutions to help here but do not provide a default for you. More info on this in our recommended Auth Plugins in the sidebar.
Using the request context
Our standard middleware adds any JSON serializable request context (like auth headers) to the context object in your resolver utils, e.g.:
export const updateProfile = createResolver(async ({
args,
context, // <- Request context (from middleware)
parseArgs,
withDefaults,
}) => {
// e.g. use the request 'context' to log out current user
const { req, userId } = context
// ...
if (!userId) throw new Error('Unauthorized')
// ...
}, updateProfileBridge)This could be a good way to check for authorization in your resolver logic itself vs relying solely on middleware.
Marking fields as sensitive
password: z.string().sensitive()In your schemas, you can mark fields as sensitive using .sensitive(). This will:
- Exclude the field from appearing in the GraphQL schema, introspection or queries
- Mark the field as strippable in API resolvers / responses (*)
- Mark the field with
isSensitive: truein schema introspection
- ‘Strippable’ means when using either
withDefaults()ORapplyDefaults()/formatOutput()with the{ stripSensitive: true }option as second argument. If none of these are used, the field will still be present in API route handler responses, but not GraphQL.
Further reading
From our own docs:
Relevant external docs: